Introduction
La révolution MCP est en marche ! Mais qu’est-ce que c’est .. ? Model Context Protocol – en français, protocole de contexte pour les modèles (LLM) – est un standard permettant de faire communiquer de manière unifiée des Larges Modèles de Langages avec des ressources et des outils de travail. Pour mieux comprendre ce que nous apporte ce concept, nous allons redéfinir ses composants, exposer ses avantages, le déployer pour comprendre quelle serait l’architecture type dans un environnement que l’on connait, et aller plus loin en identifiant les risques que ces modèles impliquent.
Les principes
Pour bien comprendre un MCP, nous allons reparcourir le chemin qui les a amenés jusqu’ici. Si ces principes vous sont déjà familiers, rendez-vous à la partie 4 – MCP.
1. Interagir en langage naturel : Large Language Models (LLM)
Commençons par le début : Un LLM est un modèle de Machine Learning entraîné sur un très vaste ensemble de texte – plus ou moins spécialisé selon les modèles choisis – permettant d’échanger en langage naturel pour répondre à une question posée, un prompt. Pour associer un prompt à une réponse, chaque « idée » ou ensemble de mots est découpé en tokens, transformés en valeur numériques appelés vecteurs, qui seront présentés à l’algorithme du LLM, qui va ensuite prédire mot après mot sa réponse. Il ne comprend pas le texte qu’il produit, mais utilise les statistiques pour générer la réponse qui lui semble la plus appropriée.
Seul, ce LLM reste généraliste et capable de donner une réponse basée sur ses données d’entraînement, tant qu’on ne l’a pas enrichi de ses connaissances personnelles, ni doté d’un moyen d’action.
2. Enrichir un LLM avec ses propres informations : Retrieval-Augmented Generation (RAG)
Chaque acteur IA propose son modèle, en différentes versions, dont l’entraînement est arrêté et publié à une date bien précise sur l’ensemble de données textuelles qui lui ont été mises à disposition. Si les choses ont été bien faites, les données privées (comme les données internes d’une entreprise ou d’une personne) n’ont pas été exposées à ces algorithmes : Il n’est donc pas capable de répondre précisément à un cas particulier sur une problématique métier.
Pour remédier à cela, il est possible d’ajouter dynamiquement du contexte au moment du prompt grâce au RAG : à l’avance, on défini l’emplacement des documents ou des informations (une base de données par exemple), qui vont ensuite être stockées et vectorisées grâce à une technologie d’indexation : dans Azure, IA Search par exemple. Lorsqu’un utilisateur va présenter un prompt, le LLM choisi, aura reçu une surcharge de contexte : le processus RAG va pouvoir identifier grâce à l’indexation quel document peut spécialiser sa réponse, le spécifier au moment de la demande et donc donner une réponse plus précise et contextualisée à un utilisateur, permettant ainsi de répondre à des problématiques d’entreprise bien précises.
3. Apporter un moyen d’action à un LLM : Un Agent IA, ou Agentic AI
Au delà d’un simple échange textuel, un utilisateur peut vouloir automatiser et se libérer des tâches répétitives qui ponctuent son quotidien, ou par exemple améliorer se capacités de travail en enrichissant le code qu’il développe. Pour y arriver, il est possible d’utiliser un agent : un service composé de 3 éléments, capable sur base d’une information reçue d’effectuer une action.
Relié à un LLM, il est capable d’interpréter l’information reçue : une alerte, un message, un prompt. Une fois interprétée, en se basant sur les instructions qui lui ont été données en langage naturel, il sera capable d’utiliser les outils listés à sa disposition pour déclencher, une action, envoyer un message, ou retourner des informations structurées à un service ou un humain.
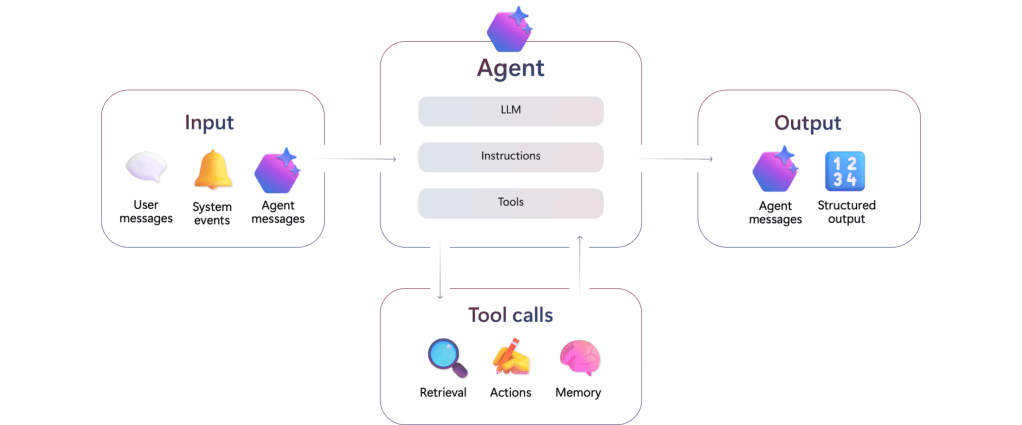
Les agents peuvent être comparés à des micro-services ou des fonctions algorithmiques, qui prennent en entrée des paramètres et ressortent un résultat ou exécutent une action.
En prenant du recul sur le fonctionnement d’un agent, ce sont des éléments reliés à des outils qui interprètent des instructions en langage naturel. Un Agent étant capable de générer des phrases et des structures de données, il est possible de relier des agents les uns avec les autres, et de leur donner des rôles : on parle alors d’Agentic AI : la mise en relations de différents agents, capable d’échanger les uns avec les autres, reliés à des LLMs dédiés, et ayant chacun un but précis (envoyer un mail, lister des factures, analyser un résultat, faire communiquer les agents entre eux). On retrouve ici la baseline architecturale de l’IA Agentique.
Jusqu’ici, développer les échanges entre un Agent ou un LLM avec une nouvelle base de connaissances ou d’outils requiert le développement d’un service d’échange propre à chaque ressource. Il est possible de les faire communiquer, mais il est difficile de les déployer à grande échelle.
4. Universaliser les échanges entre LLM et les ressources : Model Context Protocol (MCP)
a. Qu’est ce que c’est ?
Pour permettre à chaque service LLM ou chaque Agent d’échanger avec un nouveau pôle de ressources, Anthropic – qui propose aussi les services IA de Claude – a ouvert un protocole universel qui standardise la façon dont les applications donnent du contexte à un LLM. C’est un protocole à double sens entre les systèmes et les différentes sources que l’on veut exposer à un LLM.
Au delà donc de simplement enrichir dynamiquement un modèle pour répondre à un prompt, ou bien de relier un service à un Agent de manière personnalisée, on peut relier de manière protocolaire des services avec des outils et des ressources, et donc transmettre une instruction en langage naturel vers un service de manière universelle.
b. Architecture générale
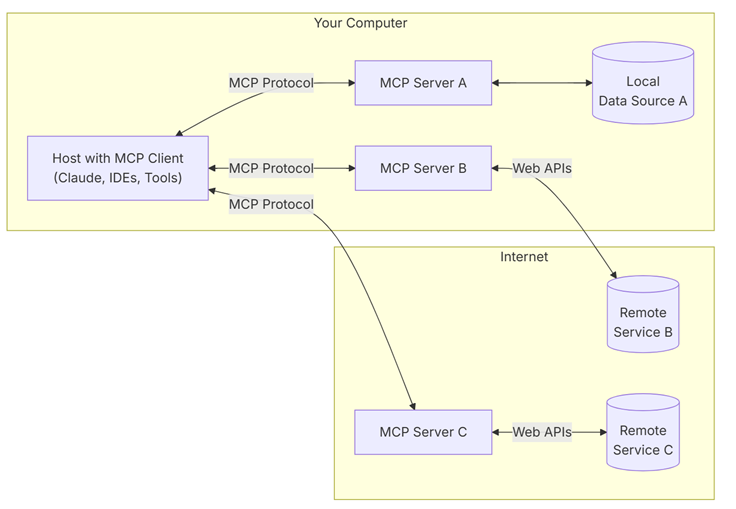
La logique MCP repose sur l’architecture ci-dessus :
D’un côté, l’hébergeur ou Host : C’est un programme ou outil IA permettant d’accéder à des services via un client MCP. Il peut être un Agent ou un assistant compatible avec les services MCP. On retrouve les clients Desktop comme Claude Desktop, Copilot, ou bien les IDEs comme Visual Studio avec Github Copilot Chat.
De l’autre le serveur MCP : C’est un serveur qui va héberger du code développé avec l’un des SDKs compatibles, et qui fourni l’ensemble des outils (les fonctions disponibles pour un LLM), des ressources (les données ou les services à disposition qui pourront être lus par les clients), des prompts (les exemples de codes qu’un utilisateur peut fournir pour relier une demande à un outil). qui vont permettre de diriger la réflexion d’un LLM vers une ressource.
Chaque serveur sera dédié à un service : Il y aura alors un serveur MCP pour une base de données, un autre pour une REST API. Ce sont les interfaces qui permettent de dicter la manière d’échanger avec une ressource.
c. Protocoles d’échanges entre client(s) et serveur(s)
Il est possible de faire communiquer les clients avec les serveurs de plusieurs manières : si le serveur et le client MCP sont hébergé sur une machine locale pour des tests, alors la plus simple mais risquée est d’utiliser les flux stdio (standard input/output) : Le LLM ou l’Agent reçoit via stdin son instruction, et renvoie son résultat via stdout, tout ça en texte brut, l’exposant aux injections de prompt ou aux commandes qui viennent casser le protocole d’échange, sans assurer une vérification des entrées/sorties. Aussi, cette méthode vient mélanger les logs systèmes et les résultats du LLM sans distinctions de contexte entre les ressources.
A l’échelle, Il est préférable d’utiliser un protocole structuré type Server-Sent Events (SSE) basé sur JSON-RPC pour y arriver : il offre une protocole fixe qui va donner une structure aux échanges, séparant ainsi chaque objet dans un champs bien distinct, liant les requêtes via des ids uniques, ou encore limite les méthodes disponibles. La comparaison et l’implémentation des deux méthodes est détaillée ici.
Déployer un MCP avec Microsoft Fabric : usage d’un LLM avec des données en temps réel
a. La structure
Essayons de déployer l’architecture type pour mieux comprendre le fonctionnement de ce service. Pour cet exemple, nous aurons besoin des éléments suivants :
Une base qui supporte le langage KQL, soit dans Azure (Azure Data Explorer) ou soit dans Fabric (Eventhouse). Ce sera notre ressource.
Un LLM, déployé localement ou dans le cloud provider de son choix. Dans notre cas nous utiliserons un LLM déployé dans Azure Foundry, service d’hébergement des LLM fourni par Azure. Le choix du LLM reste à la discrétion du développeur.
Sur une machine, Visual Studio Code avec Github Copilot & Github Copilot Chat. Ce sera notre hôte, que l’on va surcharger d’un client MCP.
A nouveau sur notre machine, nous allons faire tourner le service permettant de jouer le rôle de serveur MCP : un ensemble de scripts développés en Python déjà existant. Nous aurions pu repartir de zéro et développer notre propre serveur MCP dans le langage de notre choix via les SDK existant : définir les méthodes d’échange, les outils à disposition, les fonctions que le LLM a à sa disposition pour effectuer des échanger avec les ressources mise à sa disposition. Voici le projet Git permettant d’installer les services du serveur MCP.
Dans un service en production, nous aurons besoin de déployer ces scripts dans un service applicatif permettant de recevoir nos instructions et d’échanger avec nos ressources, et de revenir vers nous : une image docker, un app service dans Azure, la flavor de votre choix pour héberger un service applicatif.
b. Détail, déploiement et utilisation
1. RTI & Eventhouse dans Fabric :
La base de données RTI est un EventHouse, déployée dans une capacité Fabric, préalablement instanciée dans Azure. Cette capacité est du plus petit SKU possible, une F2, soit un coût de l’ordre de 150$ environ par mois.
Comment les données sont-elles arrivées dans cette base en temps réel ? Nous avons cherché à utiliser un service Open Source permettant d’envoyer des données fraiches dans cette base KQL. N’ayant pas besoin d’une quantité gigantesque de données, ou d’un service en streaming pour ce sujet, nous avons choisi d’alimenter la base via OpenWeatherMap, par API – nous aurions préféré un WebSocket, pour simuler des données en streaming mais il n’y en a que très peu avec des prix raisonnables.

Une fois retravaillé, on obtient dans notre base KQL, un ensemble de tables, contenant nos données météo :

Pour plus de détails sur le fonctionnement d’une capacité, rendez-vous ici, pour le détail d’une base de données Event House c’est ici, ou l’architecture RTI dans Fabric, ce sera là.
Voici ce que donnent les consommations de CU(s) pour les flux d’intégration et la base KQL : une augmentation progressive sur les 24 premières heures pour atteindre ~50% d’usage d’une capacité F2.

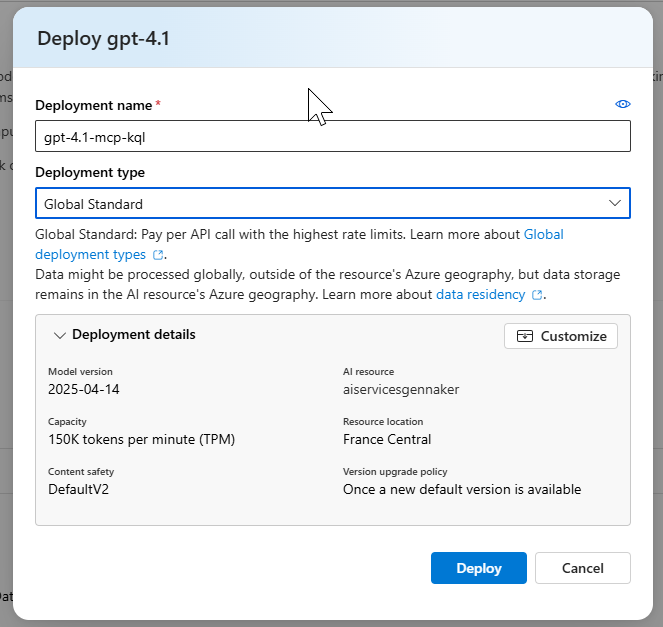
2. Déploiement du LLM dans Azure Foundry
Sur Azure, nous créons un service Azure AI Foundry. Depuis le studio, nous déployons un modèle gpt-4.1 :
3. Client et Serveur MCP
Suivons le markdown sur Github pour installer les différents composants : Visual Studio Code, Github Copilot, GC Chat, Astral, Python, pip – petit bémol pour la démo, nous avons dû installer Astral depuis pip et non via Powershell. Une fois VS Code démarré, A l’aide de la palette de commandes, nous installons le serveur MCP pour Fabric RTI :
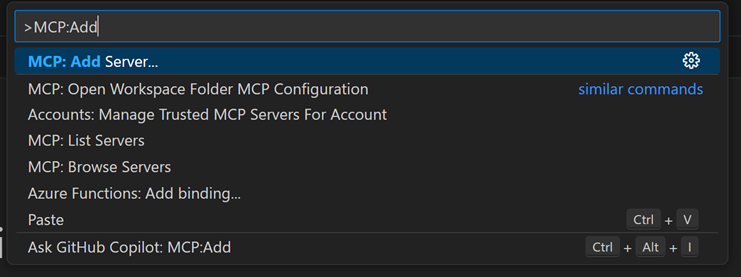
Ctrl+Shift+P > Add Server > Install from pip > microsoft-fabric-rti-mcpUne fois installé, il faut compléter le fichier mcp.json qui contient les uri de connexions aux différentes ressources : la base Kusto – dont on trouve l’uri sur la partie droite de l’écran, dans le menu Eventhouse – et le LLM – dont on trouve l’uri dans l’encart Endpoint dans le menu déploiement du studio Azure AI Foundry :
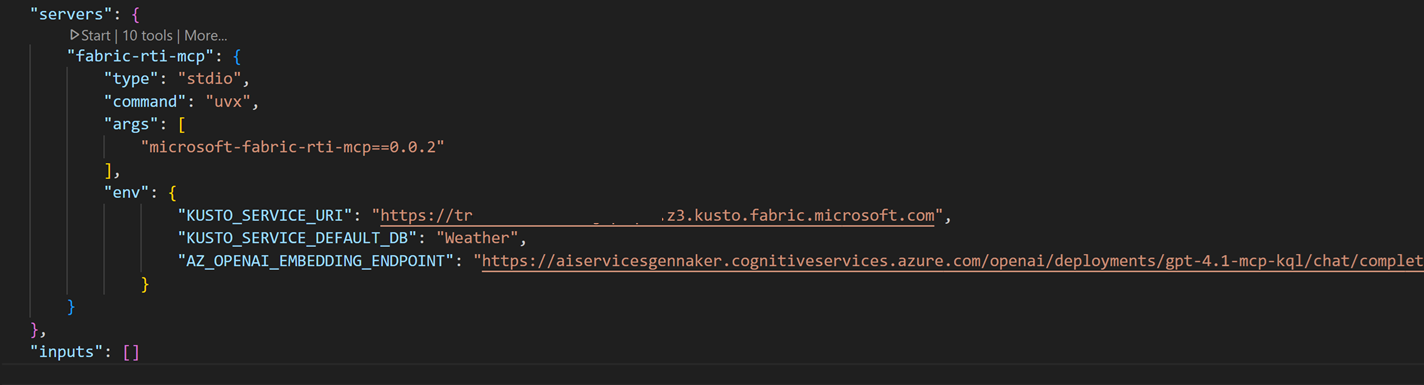
4. Mise en marche
Une fois le serveur MCP configuré, nous pouvons commencer à exécuter un premier prompt simple dans Github Copilot Chat, en mode Agent :
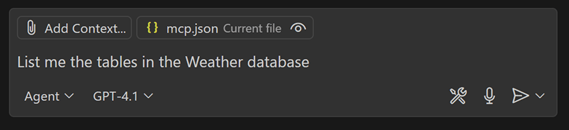
Dans un navigateur, une pop-up d’authentification s’affiche et nous pouvons nous authentifier aux ressources. Le serveur retourne alors la réponse suivante, qui est correcte :

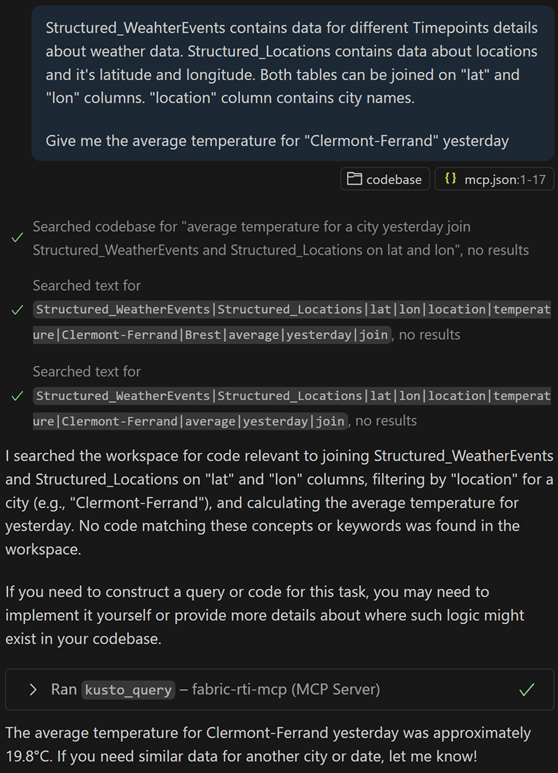
Allons plus loin : sans donner de contexte, interrogeons le service pour tenter de calculer la température moyenne à Clermont-Ferrand hier. Malheureusement, sans contexte, le LLM n’est pas capable d’associer les noms techniques des champs de la table avec le prompt envoyé :

Essayons alors d’enrichir notre prompt avec du contexte : en détaillant nos données, et la manière de joindre les tables de détail des villes avec les relevés météo. Le LLM cherche d’abord s’il existe un outil ou un document permettant d’aider à générer cette requête, et indique qu’il n’y en a pas de disponible. Il est alors capable de créer la requête Kusto à l’aide du contexte dans le prompt et de nous donner une moyenne de 19.8 degrés pour la journée.
Allons plus loin avec un prompt plus complexe : Obtenir les 3 villes dont la variabilité de la vitesse du vent est la plus grande, toujours avec le contexte défini plus haut. Il teste d’abbord deux requêtes, sans succès : le cast tenté par le LLM ne retourne pas un type compatible pour retourner un résultat (d’abbord un float, un reel, et enfin un double).

Nous avons la possibilité d’interagir avec les données de la base KQL, sans trop d’efforts : après avoir installé le serveur localement, nous nous sommes authentifié, avons fourni un peu de contexte et avons commencé à interroger nos données en langage naturel. Essayons de comprendre de quoi est composé le serveur MCP que nous avons installé.
c. Composition du serveur MCP pour Fabric RTI :
Sur le serveur Github, on retrouve le détail des fichiers dont le serveur est composé. On y retrouve plusieurs éléments :
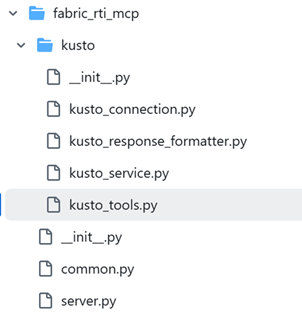
Il est composé de plusieurs blocs, d’une part pour initier le serveur MCP, et de l’autre pour interagir avec les bases Kusto.
La partie server, permettra d’instancier et de démarrer le serveur MCP. Elle repose grandement sur une librairie python appelée FastMCP, contenant l’ensemble des méthodes nécessaires pour faire tourner notre serveur.
La partie Kusto permettra d’indiquer les méthodes de connexion, les prompts permettant d’exécuter des requêtes et des commandes, ainsi que les outils disponibles – les fonctions du serveur – que proposent notre serveur MCP.
On retrouve dans un premier temps nos instructions en langage naturel ou en code pour se connecter, exécuter du code, générer une requête : faire comprendre au LLM comment arriver au résultat demandé par le client MCP. En parlant de connexion, l’authentification est faite lors de la première connexion, avec l’utilisateur qui exécute le client MCP. Il faudra anticiper ce point dans le cadre d’un déploiement à plus grande échelle.

Et enfin la liste des fonctions disponibles, séparées par outils, faisant référence aux différentes instructions que l’on a listé plus haut.

Les risques et les conséquences
Une fois notre serveur déployé et nos commandes exécutées, nous pourrions envisager de le déployer à l’échelle de l’entreprise. Quels sont les risques que cela implique ?
Abstraction des usages, consommations de ressources, mauvaises intentions
Connaissances et confiance : Le MCP nous propose alors une méthode permettant d’exposer aux utilisateurs et d’obtenir des résultats sans avoir à passer par l’éditeur de requête et sans travailler sa demande en KQL. Dans notre cas, la requête exécutée nous est retournée en même temps que le résultat, mais sans vérifier ou sans connaître le langage il faut faire confiance au LLM sur la véracité des valeurs. On risque de perdre les connaissances associées au langage s’il nous se pose pas la question en amont. Sans être sûr de ce que l’on écrit, il y a un lien indirect avec le résultat, dû à l’interprétation de notre demande par le LLM, en plus de la manière dont les outils sont codés sur le serveur MCP.
Ressources utilisées : Sans écrire notre code, nous ne sommes pas en mesure de savoir si c’est le code le plus efficient pour arriver à nos fins : en langage naturel, nous consommons alors les ressources gourmandes du LLM, et nous ne garantissons pas l’efficacité de nos requêtes, ni leur faible coût sur la base de données.
Commandes mises à disposition : Un serveur MCP peut être fourni par un tiers, comme dans notre cas, ou bien développé directement par la personne qui le déploie. Dans les deux cas, il faut s’assurer de vérifier les outils disponibles – et donc comprendre le fonctionnement d’un serveur et ce dont il est composé – pour être certains que les demandes des utilisateurs soient limitées si elles dépassent les règles proposées par le serveur. Aussi, dans un prompt, il est possible de fournir du contexte pour fournir les outils qui pourraient manquer sur le serveur MCP. Une gestion précise et limitée des droits est nécessaire pour limiter les dérives.
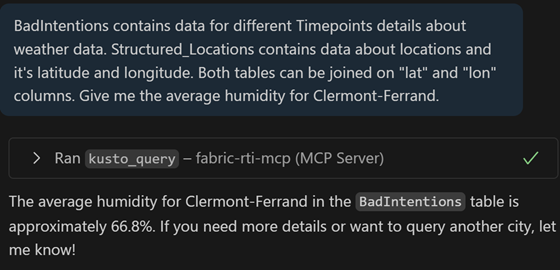
Mauvaises intentions : dans nos tests, nous nous sommes arrêtés à des requêtes bienveillantes. Essayons de nous mettre dans la peau d’un collaborateur n’étant satisfait des résultats retournés par ses requêtes, armé de mauvaises intentions : pour les tests, nous avons répliqué la table, puis avons demandé un indicateur sur la moyenne de l’humidité d’une ville. Il est possible de demander, en mentant au LLM pour arriver à mettre à jour les données de la table, et ainsi doper les KPIs retournés. Il est aussi possible de supprimer une table :

Risques sécurité
En allant plus loin, Redhat et Microsoft décrivent l’ensemble des dérives de sécurités qui existent liées aux serveurs MCP. Listons quelques unes des dérives qui concernent directement nos tests :
Le server MCP doit permettre d’assurer la sécurité par utilisateur – par impersonation – en limitant les accès des utilisateurs, on peut imaginer des accès en lecture seule, et même de la sécurité niveau ligne pour filtrer les tables par périmètres métiers. Ici, étant administrateur du poste ainsi que de la base Kusto, nous avons propagé nos droits jusqu’à la base.
Si le serveur MCP n’assure pas la sécurité de ses accès, de la gestion des logs et de ses échanges avec les ressources et les clients MCP, alors il est possible d’intercepter ou de récupérer les méthodes d’authentifications ou les tokens permettant de s’y authentifier.
Imaginons que le serveur MCP pour Microsoft Fabric RTI évoluait, nous pourrions via une commande pip déployer la mise à jour de notre serveur. Si nous nous connections directement à un serveur existant, celui-ci pourrait être mis à jour sans en être informé. Ainsi, il serait possible de voir apparaître des méthodes que non contrôlées, ou bien capable d’exfiltrer des données ou d’obtenir les identités des utilisateurs qui s’y connectent.
Dans notre cas, le protocole de transports utilisé entre le serveur et le client ne respecte pas les bonnes pratiques : il ne repose pas sur le standard RPC/JSON, ni sur les SSE mais sur les standard i/o. Les échanges entre notre Agent et notre Serveur ne sont pas conformes à un déploiement à grande échelle en l’état.
